2024. 5. 17. 12:33ㆍ논문리뷰
CVPR2023에 하이라이트 페이퍼로 소개된 메타의 이미지바인드 one embedding space to bind them all 논문에 대해 리뷰를 시작하겠습니다.
아래는 제가 참고한 자료에 대한 url입니다.
논문 paper: https://arxiv.org/abs/2305.05665
ImageBind page: https://imagebind.metademolab.com/demo?modality=I2A
참고 자료(ImageBind): https://youtu.be/AeJxJBPBzeo?si=W6qvfR6MTEPvgtGu
참고 자료(CLIP): https://youtu.be/HkkaKI6NN-8?si=ivhYTExv3OTdQ4to
발표자료는 제가 논문 세미나를 위해 열심히 만든 자료입니다.
참고만 해주시면 감사하겠습니다.
틀린 부분도 있을 수 있습니다. 부족하지만 열심히 읽고 리뷰한 논문 재밌게 봐주세용.
Introduction
이 논문은 처음부터 아주 감성적인 문장으로 시작되는데요.
'한 장의 이미지를 통해서 소리나 텍스쳐등 여러 감각을 느낀다.'
이문장을 통해 우리가 인공지능을 어떠한 general ai처럼 사람과 유사하려면 이미지 한장을 통해서 여러가지 감각을 만들어내야하는 것이 아닌가 라는 의문점을 갖으며 시작을 하게됩니다.
먼저 아주 간단하게 설명을 해드리면 이미지 바인드는 보시는 것처럼 이미지나 비디오와같은 영상적인 정보와 데이터 text, depth, heat map, IMU, audio 같은 데이터들의 페어에 대해 학습을 시키면 원래 페어가 없었던 depth나 text, 또는 heatmap이나 audio 와의 관계, 즉 pair를 이루지 않은 modality간의 연관성 얻을 수 있었다 라는게 이 논문의 핵심입니다.
Related Work(1) - CLIP
첫번째로 관련된 연구로 CLIP이라는게 있는데요.
이제 이미지 바인드는 clip을 그대로 가져와서 모달리티 구성만 추가 했다고생각하시면 됩니다.
먼저 클립은 Contrastive Learning으로 인해 Zero-shot Classification을 효과적으로 적용하였으며
대규모 데이터셋에서 텍스트와 이미지 간의 관계를 학습해 이미지에 대한 텍스트 classification을 하거나, 텍스트를 주어 이미지 retrival을 수행할수 있는 모델이라고 생각하시면됩니다.
이미지들의 미니배치가 있고 이미지에 상응하는 페어가 되는 텍스트 미니배치가 입력으로 주어집니다.
인코더를 통해 미니배치들의 representation을 뽑아냅니다.
예를 들어 첫번째 강아지이미지와 첫번째 강아지 텍스트는 페어한 데이터이므로 Positive Pair가 되고
첫번째 이미지에 대한 나머지 텍스트들 즉 쌍이 맞지 않은 나머지들은 Negative Pair가 됩니다.
그래서 총 NxN개의 페어들중 대각선의 행렬은 각 이미지,텍스트의 맞는 쌍이므로 Positive Pair가 되고 나머지전체 n제곱에서positive pair를 뺀 나머지 n제곱-n개는 Negative Pair가 됩니다.
N개의 Positive Pair의 코사인 유사도를 최대화 하며 나머지 N제곱−N Negative Pair의 코사인 유사도는 최소화시키며
학습을 진행시키게 됩니다.
이런식으로 될경우 같은 차원에 있는 같은 이미지와 텍스트끼리 페어는 가깝게 위치하게 되고 쌍이 맞지 않은 다른 페어끼리는 멀리 위치하게 되는 contrastive learning이 진행되고
이들의 similarity score에 cross entropy 를 계산해서 그걸 optimize하는 방향으로 텍스트 인코더랑 이미지 인코더를 동시에 학습을 시키는 겁니다
다시말해 이미지와 텍스트 멀티모달의 임베딩 스페이스를 학습한다고 생각하시면됩니다.

이전 슬라이드는 contrastive하게 pretraining 시킨 부분이었고요 inference부분을 보시면 클립은 zero shot prediction을 했습니다. zero shot prediction은 예를 들어 설명드리면 cifar10을 갖고 텍스트 classification을 진행한다 생각하면
training data에 사용하지 않은 이미지데이터를 가지고 이미지 인코더에 동일하게 들어가게돼서 이미지에대한 representation을 뽑게 됩니다.
텍스트는 cifar10클래스 총 10개에 대해 미리 학습된 텍스트 인코더에 넣어서 10개의 텍스트 라벨에 대한 representation을 다 출력하게 됩니다. 이전과같이 이미지에 대한 10개 클래스의 representation의 각각의 Cosine Similarity를 측정해 Cosine Similarity 값이 가장 크게나오는 class가 출력되도록 할 수있는데요.
이런 식으로 training data를 사용하지 않고도 prediction이 가능하다 라는것이 zero shot prediction이라고 설명할 수 있습니다.

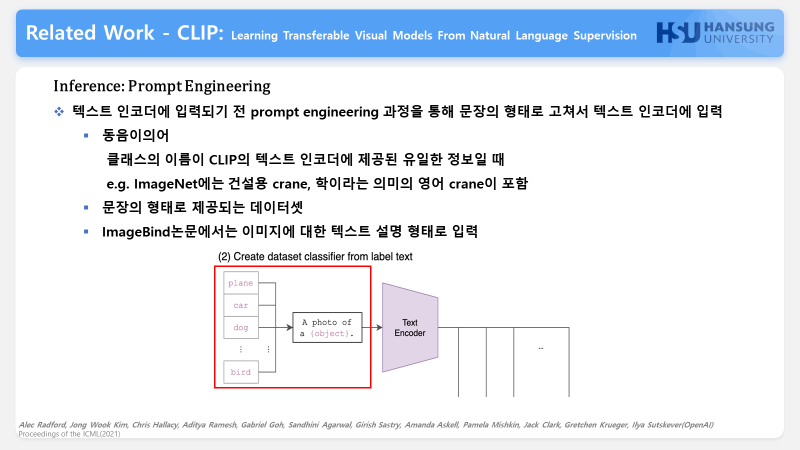
이제 텍스트들을 사전에 학습된 인코더에 넣기전에 어떤 과정을 거쳐서 텍스트 인코더에 넣어주는데요.
텍스트들을 문장형태 a photo of a 라는 문장의 형태로 고쳐서 넣어주게 됩니다. 이 부분을 prompt engineering이라고 하는데 두가지 문제들이있어서 이제 인코더에 입력으로 주기전에 prompt engineering과정을 진행하게 됩니다.
첫번째로는 동음이의어의 문제입니다.
텍스트가 CLIP의 텍스트 인코더에 제공된 유일한 정보일 때, 문맥의 부재로 인해 어떤 단어 의미를 의도하는지 구별할 수 없게 되는데요.
예를 들어 ImageNet에는 건설용 크레인과 학이라는 의미의 영어 crane이 포함되어 있습니다.이럴경우 제대로된 inference가 안될수있습니다.
두번째로는 이제 학습데이터로 인터넷에서 긁어오는 데이터를 사용하는데 인터넷에서는 이미지와 함께 제공된 텍스트가 단어 하나만으로 이루어진 경우가 상대적으로 드물다는 것입니다. 문장형태로 보통은 쓰기 때문에 텍스트를 인코더의 입력으로 줄때는 문장형태로 입력이 됩니다.
ImageBind논문에서는 이미지에 대한 설명 형태의 텍스트로 입력 text prompt를 사용합니다.
Related Work(2) - Audio CLIP
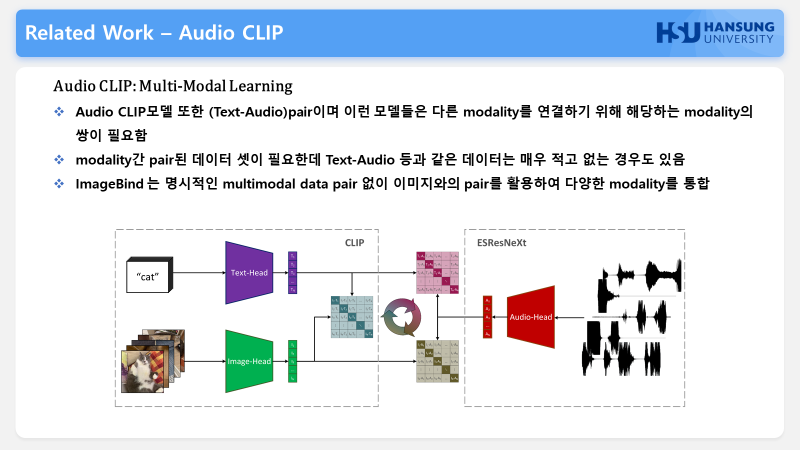
다음은 Audio clip으로 오디오를 CLIP 프레임워크에 추가하여 제로샷 오디오 classification이 가능합니다.
audioclip에서 Text-Audio와 같은 데이터는 매우 적고 없는 경우도 있으며 Text-Image에서 얻은 정보를 Text-Audio에서는 활용할 수 없고 다른 모달리티를 연결하기 위해 해당하는 모달리티의 쌍이 필요합니다.
이러한 모델들은 모달간의 데이터 쌍이 무조건 필요했지만 ImageBind는 multimodal data pair 없이 이미지간의 pair들을 활용하여 다양한 modality를 통합 할 수 있습니다.
이러한 모델들은 모달간의 데이터 쌍이 무조건 필요했지만
ImageBind는 명시적인 multimodal data pair 없이 이미지를 활용하여 다양한 modality를 통합
Method
이러한 클립의 형태를 그대로 가져와서 모달리티구성만 추가 한게 이미지 바인드입니다.
1) 이전의 연구 대부분은 clip과같이 이미지와 텍스트를 고려하지만, 이미지 바인드는여러 모달리티에서의 제로샷 classification을 가능하게 합니다.
2) 모든 모달리티 간에 명시적으로 페어링된 데이터를 필요로 하지 않음
3) 공통된 embedding space에서 학습이 되면 pair되지 않은 modality들 간의 pair에 대한 similarity도 알 수 있음
Contribution
이전의 연구와다르게 여러모달리티 각각에 대해 학습하지 않고 이미지와 pair된 데이터만 갖고 하나의 공통된 임베딩공간에서 의 학습을 하면 기존에 페어되지 않은 각각의 모달에대해서도 연관성을 얻을 수있다.

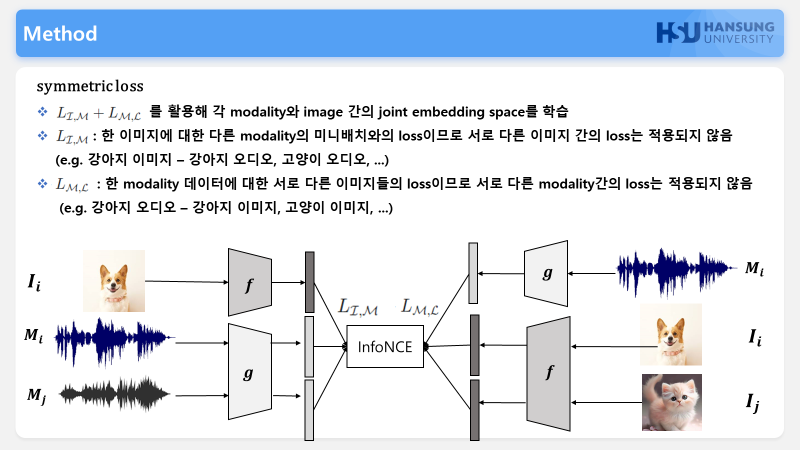
모든 학습은 이미지를 기준으로 진행되는데요, 학습에는 이미지와 모달리티간 pair를 사용하며 여기서 I는 이미지, M은 이미지를 제외한 나머지 modalities입니다.
아래 그림을 예로 들어 설명드리겠습니다.
강아지 사진이 Ii이고 그에맞는 강이지소리가 Mi일때
pair가 맞지 않는 고양이 소리가 Mj로 입력될경우 f,g 인코더로 들어가게 됩니다.
후에 인코더의 출력은 각 모달별로 다른 인코더를 사용하기 때문에 loss입력에 맞는 동일한 차원으로 맞춰주기위해 인코더의 linear projection head를 거쳐 loss에 를 계산하게 됩니다.
loss 는 InfoNCE를 사용합니다. 소프트맥스의 일종이라 생각 하시면되는데
positive pair(i=i)로 같은 의미를 갖는 image embedding qi와 다른 modality의 embedding ki의 내적(코사인 유사도)으로, 두 임베딩 유사하면 1에 가까움 LI,M은 0에 가까워져 loss는 0에 수렴하게 됩니다.
negative pair로 mini batch 안에서 qi와 pair를 이루지 않는 다른 modality의 embedding과의 내적 (코사인 유사도)
분모는 전체 pair의 내적(positive pair + negative pair), 분자는 positive pair의 내적이 되어 loss가 0에 수렴하도록 학습이 진행됩니다.

이미지 바인드에서는 symmetric loss를 적용해 각 모달리티와 이미지간의 공통된 임베딩 스페이스를 학습합니다.
한장의 강아지 이미지에 대해서 강아지 오디오, 고양이 오디오, 등 여러 오디오 데이터를 페어를 이루어 loss를 구하면 서로 다른 이미지 간의 loss는 적용되지 않은 문제가 있고
반대로 하나의 강아지 오디오에 대해 강아지사진 고양이사진등 여러 이미지에대해 loss를 구하게 되면 다른 오디오에대한 loss가 구해지지 않으므로
이 두가지 loss를 구해 하나의 공통된 임베딩 스페이스를 구성하여 학습을 진행하게됩니다.
이미지 바인드는 학습과정에서 이미 학습된 이미지와 텍스트 인코더를 가져와 가중치를 freezing시킨수 다른 모달리티의 인코더를 업데이트 시키는 방향으로 학습을 진행합니다.
이미지 바인드의 저자는 (이미지, 모달1), (이미지, 모달2) 학습을 통해 (모달1, 모달2)간의 관계도 얻을수 있다는 것을 발견
저자들은 zero-shot text-audio classification에서 (audio, text) data pair를 사용하지 않고 SOTA 달성했다고 합니다.
결국 이미지 바인드는 이미지와 모달 간의 페어만을 사용해 한공간에 매핑된 공통된 임베딩 스페이스를 구성해 학습하고 이를 통해 페어되지않은 모달간의 연관성을 얻어 제로샷 classification이 가능하다 라는걸 발견했습니다.

Implementation Details (Dataset, Encoder)




Experiments
이제 실험 결과입니다.
이전의 모델처럼 모든 modality에대해 text와 짝 지어진 train방법과 구별하기위해 ImageBind에서는 Emergent zero-shot classification이라고 명명.
표를 보시면 파란 부분으로 색칠된부분은 페어가 이뤄지지 않은 데이터 쌍으로
위의 결과는 각 modality의 분류를 텍스트로 했을 때의 성능을 말하고 있습니다.
어떠한 이미지가 있을 때 이 이미지를 올바르게 텍스트로 표현이 가능한지,
어떠한 소리가 주어졌을 때 이 소리를 올바르게 텍스트로 표현 할 수 있는가,
어떠한 depth영상이 있으면 이 depth영상을 올바르게 텍스트로 표현할 수 있는가,
에 대해 실험한 결과라고 보시면 됩니다.
ImageBind는 강력한 emergent zero-shot classification 성능을보이는것을 확인했습니다.

아래의 결과는 Embedding space arithmetic입니다.
첫줄을 보면 '과일 사진이미지이미지' + '새 울음소리오디오오디오'를 더해 만든 embedding과 가장 가까운 이미지 embedding 이라고 보시면 됩니다.
저의 느낀점은
이전 모델 한계점으로 명시적인 데이터셋이 부족해서 이 논문을 제시했다 했는데 약간 어떻게 보면 당연한 문제점을 갖고 아이디어를 냈다는게 신기했습니다.
클립은 2021년도에 나온 모델이고 2023년도에 나온 이미지바인드가 클립이아닌 이후에 나온모델을 사용했으면 더 성능이 좋지 않았을까 생각이 듭니다.
